YouTube RAG Chatbot
An end-to-end Retrieval-Augmented Generation system that transforms YouTube videos into interactive, searchable knowledge bases.
📌 Project Overview
Enabled by natural language processing, this system allows users to "chat" with any video. It provides accurate, cited answers complete with clickable timestamps, effectively solving the problem of information discovery in long-form video content.
✨ Key Features
🚀 Speed
Parallelized transcription using multi-threaded Whisper API calls reduces ingestion time significantly.
🧠 Intelligence
Powered by LangChain and Pinecone for semantic retrieval, ensuring the AI finds the most relevant context.
🛠️ Governance
Built-in FastAPI endpoints for resource cleanup, index health monitoring, and system management.
🛠️ Technologies Stack
- FastAPI, LangChain
- yt-dlp, FFmpeg
- OpenAI Whisper
- Pinecone (Vector DB)
- OpenAI embedding model-text-embedding-3-small
- GPT-4o / GPT-4o-mini
📊 System Flow
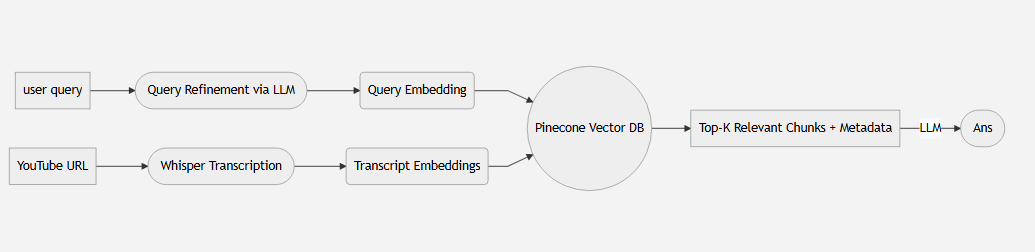
🧠 RAG Architecture
1. Ingestion Data Prep
- Audio: Extracted via
yt-dlpand processed viaFFmpeg. - Whisper: Chunks (180s) transcribed in parallel for maximum throughput.
- Semantic Chunking: 1000-char segments with 200-char overlap via
RecursiveCharacterTextSplitter. - Indexing: Vectors stored in Pinecone with deep-linked metadata.
2. Retrieval Semantic Search
- Cosine Similarity: Pinecone identifies relevant chunks based on query embeddings.
- Top-K: Fetches top 3-5 segments with precise metadata.
3. Generation Synthesis
- Augmentation: Combines the query with retrieved facts into a single context-aware prompt.
- Citation: GPT generates answers restricted to the provided context with timestamp links.
📦 Installation
Ensure you have Python 3.9+ and FFmpeg installed.
# Clone & Enter
git clone https://github.com/InfinityJais/youtube-chatbot-rag.git
cd youtube-chatbot-rag
# Environment
python -m venv venv
source venv/bin/activate # or venv\Scripts\activate on Windows
# Dependencies
pip install -r requirements.txt
# Start Server
uvicorn main_api:app --reload🧭 Project Roadmap
🔹 Version 1.0 Current
Stable RAG pipeline, Whisper integration, and basic frontend. Focus on accuracy and citation reliability.
🔹 Version 2.0 Planned
- Observability: Tracing LLM calls, latency, and token monitoring.
- Memory: Short-term conversational context and long-term user preferences.
- Multi-Agent: Specialized agents for retrieval vs. reasoning.